OllamaAI翻译(离线)
Ollama官网地址
前言:本翻译源为离线AI翻译,需要下载Ollama软件和AI离线大模型
由于 Ollama 暂未提供界面,故而目前只能通过 控制台 / 终端 进行操作
如果对于需要页面操作的需求用户较多,我们会考虑开发界面端,欢迎反馈 ~
AI模型信息 随时间推移,官网可能会有变动,此处仅供参考,具体以官方文档为准
| 模型名称 | 模型型号 | 模型大小 | 命令执行 |
|---|---|---|---|
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Llama 3 | 8B | 4.7GB | ollama run llama3 |
| Llama 3 | 70B | 40GB | ollama run llama3:70b |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Phi 3 Medium | 14B | 7.9GB | ollama run phi3:medium |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Solar | 10.7B | 6.1GB | ollama run solar |
使用前提
名词介绍: RAM(Random Access Memory)通常指的是电脑中的内存条
按照官网说明,AI模型对电脑要求
7B 模型型号至少需要 8 GB 可用 RAM 来运行
13B 模型型号至少需要 16 GB 可用 RAM 来运行
33B 模型型号至少需要 32 GB 可用 RAM 来运行
1.下载安装 Ollama
Ollama官网:https://ollama.com/
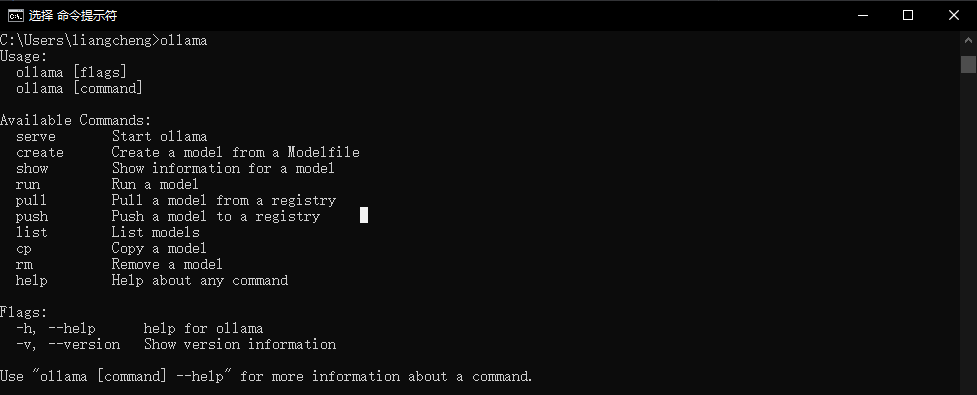
安装完毕后,打开电脑控制台 / 终端,输入:ollama
出现如下界面则表示安装成功
2.通过 Ollama 下载AI大模型
打开电脑控制台 / 终端,复制上面模型列表中的对应模型命令执行
Ollama 其他命令
查看当前下载的模型列表
ollama list下载模型 (此命令还可用于更新本地模型。只有差异才会被拉出。)
ollama pull xxx删除模型
ollama rm xxx